|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
от Mike Aubert |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Добро пожаловать в одиннадцатую статью моей серии «Изучи сервер Windows SQL 2000 за 15 минут в неделю». В течение последних нескольких недель мы изучали процессы резервного копирования и восстановления баз данных. И хотя информация по резервному копированию могла бы подождать до конца нашей серии, у меня было чувство, что резервное копирование является важнейшей темой, которую стоило довести до вас как можно скорее. Поэтому я решил поместить информацию о резервном копировании в начало нашей серии, а не в конец. В достаточной мере зная тему резервного копирования, мы теперь изменим направление и рассмотрим, как на сервере SQL создаются объекты. В статью этой недели вошли следующие темы:
Концепция модели реляционных баз данных До сего момента мы фокусировали свое внимание на физической модели базы данных, которая включала в себя такие вещи, как файлы и группы файлов. Физическая модель отражает, как данные хранятся и какой способ доступа к данным наиболее эффективен. Сейчас мы перейдем к рассмотрению реализации логической модели базы данных, которая включает в себя такие объекты, как таблицы и взаимоотношения между ними. Логическая модель только моделирует структуры реальных данных – она не заботится и не зависит от конкретной реализации Системы управления базами данных. Например, я могу использовать одну и ту же логическую модель как для создания баз данных в сервере SQL, так и в программе Access и я буду думать о них, как о совершенно одинаковых базах данных, настолько, насколько глубоко описана логическая модель. Однако физическая модель этих двух баз данных будет значительно отличаться – база данных программы Access может быть представлена в виде всего одного файла, в то время как база данных сервера SQL будет состоять из нескольких различных файлов, иногда распределенных между несколькими жесткими дисками. Другим примером может служить база данных сервера SQL в которую добавлен какой-либо файл данных. В то время как физическая модель базы данных при этом измениться, его логическая модель останется неизменной. Важно отметить здесь, что физическая реализация базы данных и логическая реализация представляют собой отдельные концепции, которые являются, в большой мере, независимыми друг от друга. Думаю, я уже говорил об этом, но если нет, то знайте – сервер SQL является системой управления реляционными базами данных (RDBMS – Relational Database Management System). Поэтому базы данных, с которыми мы будем работать, это реляционные базы данных. И хотя понимание того, как разрабатывать реляционные базы, является наиважнейшей темой, наша серия статей относится к администрированию сервера SQL (экзамен 70-228) и затрагивает аспекты только физической модели баз данных, а не логической модели реляционных баз данных (эти вопросы входят в материалы экзамена 70-229). Если сегодня вы впервые начинаете работать с реляционными базами данных и у вас нет ясного представления о концепциях их организации, я настоятельно советую вам остановиться на этом месте и найти хорошую книгу, посвященную реляционным базам данных. Вы, конечно, можете и без этого прочитать нашу серию до конца, и освоить материалы экзамена 70-228. Но, зная, как создавать логические модели реляционных баз данных, вы значительно упростите себе задачу освоения материала этой серии и, несомненно, станете более опытным администратором. Можете воспользоваться следующими ссылками, чтобы начать изучение логических моделей организации баз данных: Support
WebCast: Database Normalization Basics Типы данных сервера SQL Для каждого столбца вашей базы данных должен быть назначен «тип данных», определяющий, какие данные хранятся в данном столбце. Кроме того, тип данных отвергает данные некорректного типа (т.е. попытка сохранить букву в столбце, содержащем числа, будет отклонена). Сервер SQL поддерживает 25 различных типов данных – некоторые из них имеют больше различных свойств, чем другие. Давайте посмотрим на типы данных и на свойства каждого из них (большая часть этой таблицы является копией из справочной системы сервера SQL – Books Online):
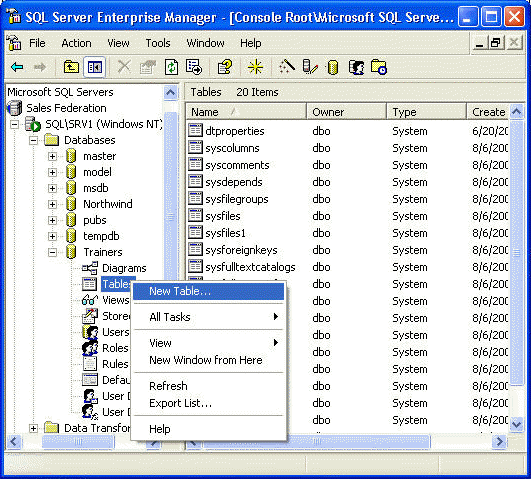
Эта таблица охватывает практически все типы данных. Однако есть два вида, которые я не упомянул в ней (это cursor и table), но они и не применяются на самом деле, так как вы не можете иметь столбец, образованный данными данного типа. Есть несколько вещей на которые стоит особенно обратить ваше внимание, говоря о типах данных из таблицы, приведенной выше. Прежде всего, в статье «Основы создания баз данных» я говорил, что максимальный размер строки в базе данных равен 8060 байтов. Для того чтобы посчитать, насколько большой может быть каждая строка в вашей базе данных и убедиться, что ее размер меньше 8060 байтов, вы можете просто сложить размеры всех столбцов и получить искомый ответ. И хотя это абсолютная правда, что строка не может занимать больше одной страницы памяти, все же есть путь обойти это 8060-байтное ограничение. Для этого можно использовать типы данных text, ntext и image (известные как “BLOB” или Binary Large Object (большие двоичные объекты). По умолчанию, типы данных text, ntext и image не хранят свои данные в тех строках, в которых они помещены, как это происходит с другими типами данных. Вместо этого строки содержат 16-битные указатели, которые перенаправляют сервер SQL на другие 8Кб страницы, где и размещаются данные. Используя в строке только указатели на хранящиеся данные, вы можете преодолеть 8060-байтное ограничение. Но будьте осторожны, типы данных text, ntext и inage сами имеют некоторые ограничения, о которых мы поговорим позднее в данной серии. Одной из отрицательных сторон данного способа является то, что, так как сервер SQL должен находить две или даже более страниц (в отличие от всего одной страницы для строк, не содержащих данных text/image) – это может значительно замедлить его работу. Практически применимым является использование этих типов данных, только если это абсолютно необходимо. Рассказывая о переменных, которые имеют версии с “n” или без “n”, давайте сравним типы данных string Unicode и non-Unicode. Если вы помните, в статье «Основы установки» одной из опций установки сервера SQL являлся выбор режима сопоставления (collation), который включает в себя выбор страницы кодировки ASCII. Типы данных non-Unicode (char, varchar и text) хранят значения ASCII из кодовой страницы для каждого знака. Кодовая страница содержит только 256 ASCII значений и пространство, необходимое для хранения одного знака равно 1 байту (2^8). Но что произойдет, если вам потребуется использование нескольких языков или у вас нет кодовой страницы ASCII, которая содержала бы все необходимые вам символы? Используя типы данных Unicode (nchar, nvarchar и ntext), вы можете хранить несколько языков и иметь доступ более чем к 256 символам. Для того чтобы добиться этого (не так как это делается в типах данных non-Unicode), типы данных Unicode имеют размер 2 байта для каждого символа, что делает возможным поддержку 65536 символов (2^16) – более чем достаточно для того, чтобы включить все необходимые вам символы для поддержки нескольких языков. (Воспользуйтесь ссылкой http://www.unicode.ord/ для того, чтобы получить больше информации об Unicode). Следующее замечание касается типов данных с фиксированной длиной и с переменной длинной. Если вы используете типы данных char или nchar, не имеет значение, как много символов вы введете, поле всегда будет использовать n байтов (или 2*n для nchar). Например, если я установил размер (т.е. n) столбца равным 10 и у меня есть три строки “Dan”, “Mike” и “Jason”, то пространство, необходимое для хранения этих трех строк будет равно 30 байтам, несмотря на то, что они содержат только 12 символов данных. С другой стороны, если вы будете использовать версию типа данных char или nchar переменной длины, то пространство, требуемое для хранения этих трех строк, будет равно 12 байтам, т.о. вы сэкономите 18 байт. Конечно, это не выглядит такой уж большой цифрой, но если у вас таблица, состоящая из многих столбцов и 100,000 строк, то выгода становится более очевидной. Дело выглядит так, что было бы хорошо все время использовать типы данных varchar или nvarchar, но тут есть оборотная сторона – время, необходимое для работы с данными переменной длины замедляет работу сервера SQL. На практике для хранения текстовых данных, размер которых не меняется от строки к строке, применяются типы данных char или nchar. Так для нашего примера с тремя строками, думаю, лучшим вариантом будет применение типа данных char – при работе с большей таблицей, в которой окажется большое количество имен, длиннее 5 знаков, выигрыш в скорости работы оправдывает потерю увеличения используемого дискового пространства. Как я уже говорил: при работе с сервером SQL многие вещи делаются для нахождения некоторого баланса, вы постоянно ищите, что даст наибольшую производительность в вашем случае. И в заключение обобщенные выводы об использовании типов данных, которые представляется мне важными. Когда вы выбираете, какие типы данных использовать, цель состоит в том, чтобы выбрать тот тип, который будет занимать наименьшее дисковое пространство и, в то же время, будет соответствовать всем возможным значениям, которые возникают (и будут возникать) за все время существования базы данных. Хорошей иллюстрацией к сказанному является выбор размера целочисленных значений. Если вы уверены, что будете хранить только значение ответа yes/no, то тип данных bit будет более чем достаточен и любой другой тип, например, smallint или int, будут только напрасно тратить дисковое пространство. Другим примером напрасного использования дискового пространства является использование типа datetime, в то время как вам достаточно диапазона и точности smalldatetime. Выбирая наименьший возможный тип данных, вы не только экономите дисковое пространство, но также уменьшаете количество страниц, образующих таблицу – что в свою очередь уменьшает время, необходимое для выполнения запросов (т.к. серверу SQL требуется меньше страниц для загрузки с жесткого диска и сканирования). Вы также должны постараться установить типы данных так, чтобы они обеспечивали для вас максимальную поддержку целостности данных. Хорошим примером является использование типов данных datetime или smalldatetime для хранения информации о дате – эти типы данных могут занимать больше пространства и использовать больше процессорного времени, чем просто дата, записанная строкой из 6 символов, но при длительном использовании правильный тип данных для даты обязательно сэкономит ваше время. Создание таблиц Раз уж у вас уже есть логическая схема в качестве отправной точки, сам процесс создания вашей таблицы выглядит достаточно просто. Запустите Диспетчер Предприятия, затем разверните ваш сервер и базу данных, в которую вы хотите добавить таблицу, затем нажмите правой кнопкой мыши на значке Tables и выбрать “New Table…” из появившегося меню.
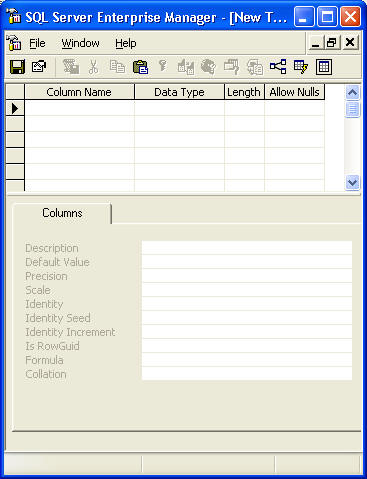
Появится окно New Table и оно будет выглядеть вот так:
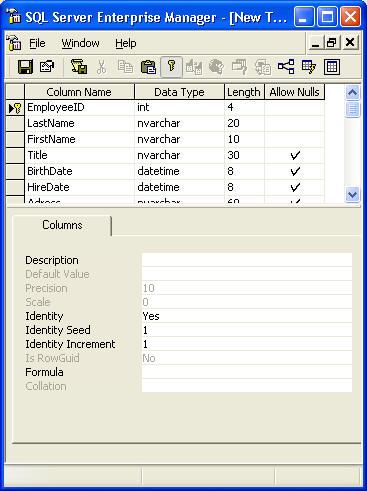
Каждая строка этого окна представляет отдельный столбец таблицы, которая создается/редактируется. “Column Name” (имя столбца) – используется для того, чтобы ввести имя столбца. “Data Type” (тип данных) – устанавливает тип данных, содержащихся в столбце. “Length” (длина) – определяет длину (или ‘n’) столбца. Для таких типов данных, как text или ntext это значение может быть изменено и определяет максимальное число знаков, которое будет храниться в столбце. Для других типов данных, таких как int и decimal, не имеющих длины, “Length” показывает размер (в байтах) необходимый для столбца. “Allow Nulls” (разрешить пустые значения) – определяет, может ли отдельный столбец содержать пустые значения. Поставленная «галочка» означает, что пустые значения в данном столбце допустимы. То есть, если вы добавляете/редактируете строку, она не обязательно должна содержать значение в данной ячейке. Если отметки нет, то любая строка, которая добавляется или редактируется, обязательно должна содержать значение в данной ячейке. Запомните, что 1, 0 и <NULL> (или ‘abc’,’ ‘, <NULL>) – это три совершенно разные вещи. Например, если 0 и <NULL> выглядят похоже, но 0 обычно означает “False” (Ложь), а <NULL> означает “No Value” (нет значения). Очень важно запомнить эти вещи, так как мы еще будем рассматривать их в нашей серии. Таблица, хранящая данные о служащих может выглядеть вот так:
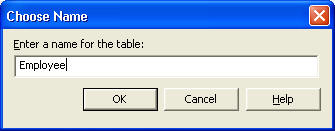
Здесь есть несколько моментов, о которых стоит упомянуть. Во-первых, если вы когда либо прежде использовали программу Access, вы должны узнать изображение ключа слева от строки EmployeeID. Это показывает, что строка (строки) таблицы являются первичным ключом (т.е. используемый столбец(ы) уникально идентифицирует каждую строку в таблице). Для установки первичного ключа выберите соответствующую строку (вы можете нажать клавишу Ctrl для того, чтобы выбрать более одной строки одновременно) и затем нажмите иконку “Set primary key” в панели инструментов. Далее, когда вы будете двигаться от строки к строке, вы заметите, что доступные опции на вкладке “Columns” меняются. Давайте рассмотрим каждую из этих опций индивидуально: Description (описание) – эта строка предназначена для того, чтобы вы могли ввести любые комментарии, относящиеся к тому, для чего используется данных столбец. Чтобы вы не написали в данном окне, оно не будет воздействовать на сервер SQL или таблицу. Default Value (значение по умолчанию) – значение, которое будет присвоено, если никакое иное значение не будет введено при добавлении строки в таблицу. Например, я могу установить значение по умолчанию “staff” для столбца Title. Каждый раз, когда будет добавляться новый сотрудник без указания его должности, “staff” будет автоматически заменять значение <NULL>. Кроме того, вы не ограничены только использованием текста для определения значения по умолчанию, вы также можете использовать функции. Очень часто используются функции GETDATE(), который возвращает текущую системную дату/время и NEWID(), который возвращает новый глобальный уникальный идентификатор. Заметьте, что если вы установите значение “Identity” (идентичность) для столбца Yes, то значение по умолчанию не будет иметь силы. Precision\Scale (точность\точность дробной части) – используется для определения точности числа и точности дробной части числа типов данных decimal и numeric. Эти опции недоступны для других типов данных. Для получения информации о том, что такое точность и точность дробной части, обратитесь к типу данных decimal в таблице, приведенной в начале данной статьи. Identity/Seed/Increment (Идентичность/Начальное значение/Инкремент) – похож на опцию AutoNumber в Access – если для столбца значение свойства IDENTITY установлено в значение Yes, то сервер SQL будет автоматически генерировать новое число для каждой вновь добавляемой в таблицу строки и записывать его в этот столбец. Каждая таблица может иметь только один столбец со свойством IDENTITY, установленным в значении Yes и этот столбец должен использовать типы данных decimal, int, numeric, smallint, bigint или tinyint. Исходное значение идентификатора (Identity Seed) определяет, с какого числа должен начать сервер SQL. Инкремент (Identity Increment) определяет, какое число должно добавляться к исходному значению для определения следующего идентификатора. Заметьте, что столбцы с идентификаторами гарантируют их уникальность только в одной таблице – две таблицы со столбцами идентификаторов могут (не обязательно) сгенерировать одинаковые числа. Другая вещь, которую следует запомнить, это то, что могут существовать большие пропуски значений идентификаторов, так как значения удаленных идентификаторов повторно не используются. Is RowGuid (строка содержит GUID) – определяет, что данный столбец содержит GUID для строк таблицы. Только одна таблица может содержать значение свойства Is RowGuid со значением Yes и тип данных для этого столбца должен быть определен как uniqueidentifier. Кроме того, вы должны также установить в качестве значения по умолчанию для данного столбца функцию NEW(). В отличие от значений идентификатора, значения GUID являются (должно являться!) уникальными для каждой строки, в каждой таблице, в каждой базе данных на каждом компьютере в мире. Formula – используется для ввода формулы, делающей этот столбец вычисляемым. В отличие от простого хранения данных, вычисляемый столбец берет формулу (например: LastName&’,’&FirstName) и генерирует значение, зависящее от введенной вами формулы. Кроме того, вычисляемые столбцы генерируются на «лету», так обновление в столбце, связанном с этой формулой вызовет автоматическое обновление вычисляемого столбца. Collation (режим сопоставления) – дает возможность устанавливать режимы сопоставления для каждого отдельного столбца в таблице. Значение <database default> устанавливает для столбца тот же режим сопоставления, что и для всей базы данных, в которой расположена таблица. Поскольку вы уже добавили все столбцы в таблицу, вы можете нажать на значок сохранения (самый левый, с изображение дискеты) в панели инструментов, после чего вам предложат ввести имя для таблицы:
После того, как вы введете имя и нажмете кнопку ОК, можете закрывать окно New Table, нажав расположенный во вложенном окне Х вверху справа. Также можете использовать меню “Window” для переключения окон или их упорядочивания. После обновления списка таблиц (F5), созданная вами таблица появится в Диспетчере Предприятия сервера SQL:
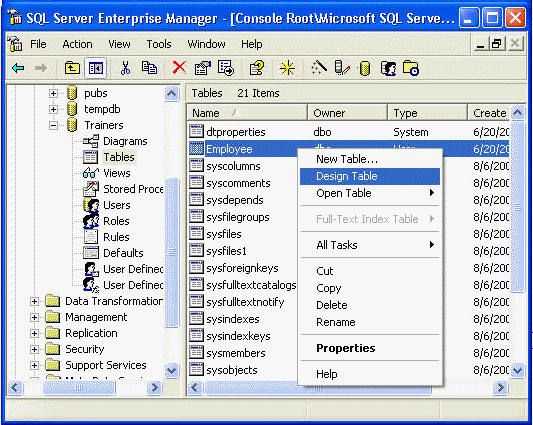
Вы всегда можете вернуться назад и отредактировать таблицу, нажав правой кнопкой мыши на ее изображении в Диспетчере Предприятия и выбрав опцию “Design Table”:
И последнее: спользование Диспетчера Педприятия не является единственным путем создания таблиц – вы также можете использовать оператор CREATE TABLE. Для получения большей информации посмотрите статьи об операторах CREATE TABLE и ALTER TABLE в справочной системе сервера SQL Book Online. Ну что ж достаточно для этой недели. На следующей мы продолжим говорить о создании таблиц, но более конкретно. Мы рассмотрим дополнительные свойства таблиц, создание связей и ограничений CHECK. Итак, как всегда… если у вас возникнут какие-либо технические вопросы, пожалуйста, присылайте их на доску объявлений сайта 2000Trainers.com SQL message board. Нетехнические вопросы, комментарии и обратная связь – по адресу моей электронной почты. Я надеюсь, что вы найдете эти статьи полезными и был бы рад узнать ваше мнение о них. Mike Aubert, MCSE, MCDBA, MCSD. |