|
|
|
от Mike Aubert |
|
|
Добро пожаловать в шестую статью моей серии «Изучи сервер Windows SQL 2000 за 15 минут в неделю». На прошлой неделе мы создали нашу первую базу данных на сервере SQL 2000. Мы изучили, какие файлы образуют базу данных сервера SQL, как данные хранятся в этих файлах и как группы файлов могут использоваться для управления файлами. На этой неделе нам предстоит изучить больший материал, так что давайте начнем. В данную статью включены следующие темы:
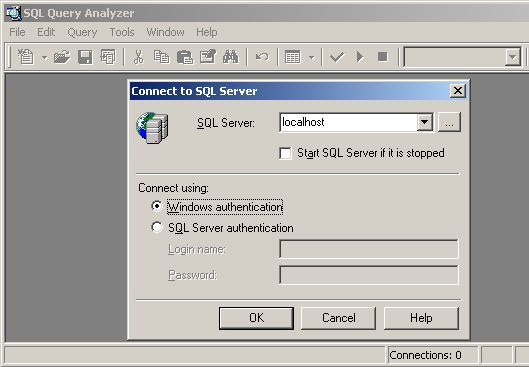
SQL и T-SQL Структурированный язык запросов (Structured Query Language), так же известный как SQL, является языком запросов и программирования. Он может быть использован для доступа, обновления, удаления и добавления данных в базы данных. SQL также может быть использован для управления RDBMS (Relational DataBase Management System – система управления реляционной базой данных). Различные базы данных могут использовать близкие версии SQL, но обычно совместимые со стандартной ANSI SQL-92 реализацией SQL, обычно называемой ANSI SQL. Вы можете сгруппировать запросы SQL в две главные категории: DDL (data definition language – язык определения данных) и DML (data manipulation language – язык манипулирования данными). Предложения DDL, в соответствии с их названием, позволяют вам определять структуру баз данных. Большинство предложений DDL начинаются операторами CREATE, ALTER или DROP. Сегодня мы рассмотрим два оператора – CREATE DATABASE (используемый для создания новой базы данных) и ALTER DATABASE (используемый для изменения существующей базы данных). Мы изучим точный синтаксис данных операторов позднее в данной статье. Предложения DML, с другой стороны, используются для манипулирования данными в объектах баз данных. Например, оператор SELECT позволяет вам запрашивать данные в базах данных, INSERT – позволяет добавлять новые данные, UPDATE – обновлять выбранные данные и DELETE – удалять данные. По мере продолжения данной серии мы с вами охватим как эти операторы SQL, так и многие другие DDL и DML-операторы более детально. Теперь мы знаем, что такое SQL, но что из себя представляет T-SQL? Упрощая, можно сказать, что T-SQL является усовершенствованной версией стандартного языка SQL для сервера SQL. T-SQL в сервере SQL 2000 позволяет использовать такие вещи, как хранимые процедуры, операторы IF и WHILE и дополнительные типы функций/данных (мы рассмотрим типы данных, когда будем создавать таблицы), которые недоступны в стандартном SQL. Для использования операторов T-SQL у нас должен быть способ посылки этих операторов к RDBMS. Одним из путей является использование утилиты командной строки OSQL. Если вы являетесь DBA (Администратором базы данных) и работали с сервером SQL 6.5, вы должны были заметить, что утилита командной строки OSQL заменила старую утилиту ISQL, которая не поддерживала многие из новых функций сервера SQL 2000. И хотя сервер SQL 2000 поддерживает OSQL, эта утилита имеет интерфейс командной строки, что вряд ли может понравиться большинству пользователей. Вы можете узнать больше об этой утилите, поискав информацию о ней по ключевым словам “osql utility” в информационной системе Book Online сервера SQL. Инструмент, который мы будем использовать в данной серии для написания, редактирования и оптимизации наших T-SQL сценариев, называется SQL Query Analyzer (Анализатор запросов). Эта утилита с графическим пользовательским интерфейсом позволяет вам запускать операторы T-SQL, создавать сценарии, которые могут сохраняться и редактироваться, а также предоставляет информацию, которая может быть использована для оптимизации как баз данных, так и операторов T-SQL. Есть два способа для запуска анализатора запросов SQL. Во-первых, вы можете просто открыть его, выбрав Query Analyzer из группы программ Microsoft SQL Server в меню Start. Когда программа откроется, первое, что вы должны сделать – выбрать сервер и ввести данные для входа в систему. Следующее окно иллюстрирует процесс подключения к локальному экземпляру сервера SQL, в котором используется аутентификация Windows.
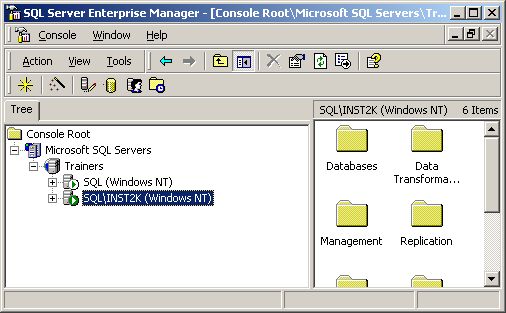
И во-вторых, вы можете получить доступ к анализатору запросов SQL из оснастки Диспетчер предприятия (Enterprise Manager). Давайте посмотрим, как это делается при создании новой базы данных при помощи T-SQL и Анализатора Запросов SQL. Чтобы начать, откройте Диспетчер Предприятия и установите соединение с вашим сервером SQL, выбрав его в дереве SQL.
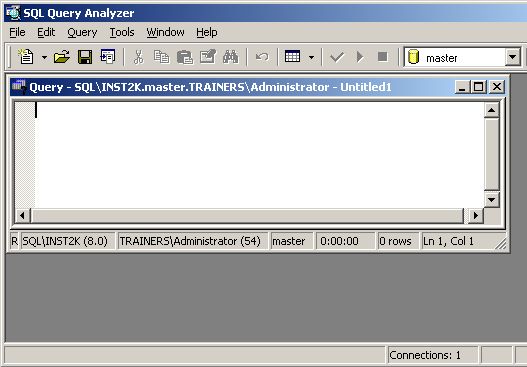
Далее, в меню Tools выберите Query Analyzer (Анализатор Запросов). Первое, на что вам стоит обратить внимание, это то, что при этом вас не попросят выбрать сервер или ввести информацию для входа в систему. Когда вы запускаете Анализатор Запросов SQL из Диспетчера Предприятия, этот инструмент автоматически использует выбранный вами в дереве SQL сервер. Кроме того, он использует те данные для входа в систему, которые вы использовали при подключении к серверу в Диспетчере Предприятия.
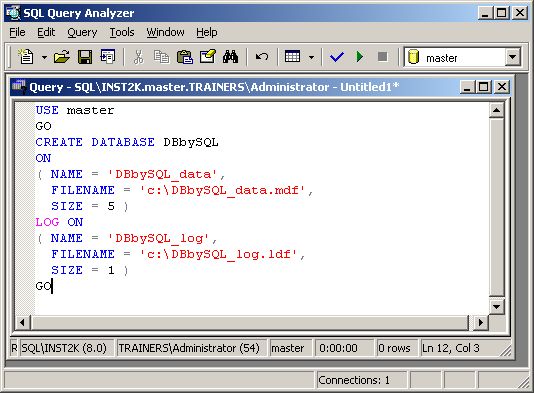
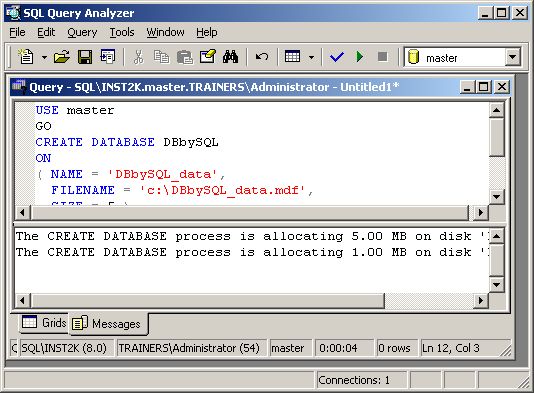
Строка состояния внизу окна Запросов дает вам важную информацию о сервере, к которому мы подключены, об учетной записи, под которой мы получили доступ и другую информацию о состоянии. Для создания базы данных мы используем оператор CREATE DATABASE. Давайте рассмотрим синтаксис данного оператора: CREATE DATABASE database_namе < filespec > ::= [ PRIMARY ] < filegroup > ::= FILEGROUP filegroup_name < filespec > [ ,...n ] Вы сбиты с толку, не так ли? Для того чтобы разобрать этот сценарий строку за строкой, изучите следующую ссылку: Transact-SQL Reference: CREATE DATABASE Вы также можете найти нужную информацию в справочной системе Book Online в разделе “CREATE DATABASE”. Например, вы хотите создать базу данных, называемую DBbySQL c файлом данных 5МВ и файлом журнала 1 МВ. Введите следующий оператор в окно запроса:
Нажмите данную ссылку, чтобы увидеть этот файл в текстовом формате. Есть несколько вещей, которые вы должны здесь отметить для себя. Во-первых, оператор USE изменяет содержание базы данных (с которой мы работаем). В этом случае, мы создаем новую базу данных, используя базу данных master. Далее, команда GO говорит Анализатору Запросов SQL выполнить текущий набор (batch) операторов Transact-SQL. Команда – это набор операторов Transact-SQL от последней директивы GO или от начала сценария. Важно знать, что GO не является оператором SQL, она является командой, которая используется для того, чтобы указать Анализатору Запросов SQL или OSQL (и ISQL также) послать текущий набор операторов Transact-SQL на сервер SQL. И последнее, на что я хотел обратить внимание в данном сценарии – это сам оператор CREATE DATABASE. Создавая базу данных, мы обычно не определяем значения всех доступных опций. Для опций, которые не определены, сервер SQL устанавливает значения по умолчанию. Также, когда вы устанавливаете SIZE (размер) файла, вы можете не писать МВ, потому что по умолчанию значение SIZE определяется в МВ (хотя для читабельности вы можете добавлять МВ, где хотите). После того, как вы введете сценарий, выберите Execute из меню Query. Результат работы Анализатора Запросов SQL будет выглядеть следующим образом:
Вот она! Теперь у нас есть новая база данных, созданная нашим сервером SQL.
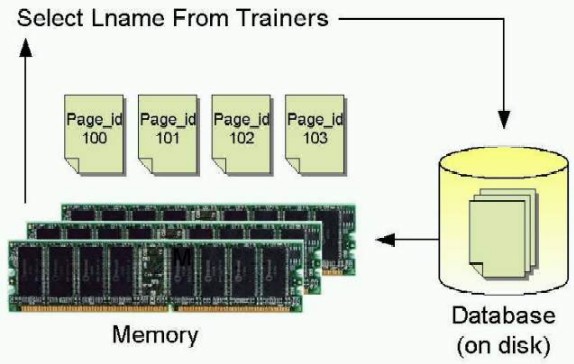
Также вы можете использовать оператор ALTER DATABASE для изменения существующей базы данных. Например, следующее предложение добавит новый файл данных к базе данных DBbySQL с размером 5 МВ и максимальным размером 50 МВ: USE master Для получения большей информации об операторе ALTER DATABASE вы можете опять обратиться к справочной системе сервера SQL Book Online. Эта информация может быть также найдена на сайте MSDN: Transact-SQL Reference: ALTER DATADASE Примечание: я собираюсь более подробно описать работу Анализатора Запросов SQL в следующих статьях. Понимание журналов транзакций В моей последней статье я дал предварительное описание того, что представляет из себя журнал транзакций. Однако мы так и не продвинулись в понимании того, что представляет из себя сама транзакция. Простейшее определение транзакции выглядит так: Транзакция – это логическая единица работы. Другими словами – это группа операторов SQL, которые выполняют одну логическую задачу. Классический пример, который чаще всего используется для описания транзакции, это банковский перевод. Предположим, что у вас есть два счета в банке (счет А и счет В) и вы хотите перевести деньги с одного счета на другой. Если вы будете выполнять два оператора SQL независимо друг от друга (один из них будет удалять деньги со счета А и другой – добавлять деньги на счет В), то возникает вероятность того, что вы успешно выполните первый оператор (удалите деньги со счета), но, по каким-то причинам не сможете выполнить второй (зачисление денег на счет). В реальной жизни это будет означать, что кому-то из клиентов банка сильно не повезет. Для разрешения данной проблемы мы можем сгруппировать данные операторы в транзакцию. Если операторы объединены в транзакцию, то либо они все успешно завершаются и транзакция являются «завершенной», либо, если один из операторов вызовет сбой, они все «возвращаются на исходные позиции» и все данные остаются в состоянии, которое у них было до начала транзакции. До тех пор, пока мы не обратимся к понятию целостности данных, этого определения будет достаточно. Журнал транзакций хранит все изменения, которые были сделаны в базе данных. Когда все операторы в транзакции выполнят соответствующие изменения в базе данных, транзакция будет завершена и это завершение будет записано в журнале транзакций. Раз уж транзакция завершена, почему необходимо сохранять сведения о ней в журнале? Для понимания этого, нам необходимо знать, что же происходить «под крышкой» сервера SQL. Когда данные запрашиваются из базы данных, вся информация хранится в оперативной памяти. Так как доступ к памяти намного быстрее, чем доступ к дисковой подсистеме, сервер SQL может поразительно увеличить свою производительность. Первый запрос данных из базы данных (запрос сделан, страницы загружены в память, данные посланы клиенту):
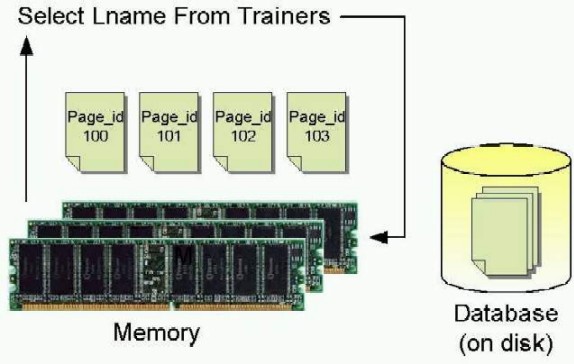
Запрос данных, которые уже находятся в памяти (страницы кэшированы в памяти, поскольку уже использовались):
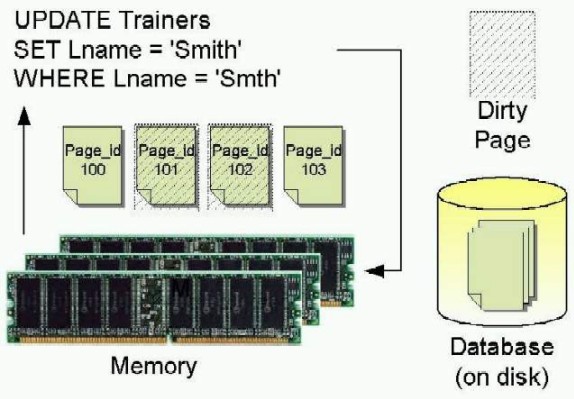
Когда вы вносите изменения в данные базы данных, сервер SQL производит изменения в данных, хранимых в памяти (не на жестком диске) и соответствующая запись вносится в журнал транзакции. Страницы в памяти, которые содержат измененные данных, называются «грязными страницами» (dirty pages).
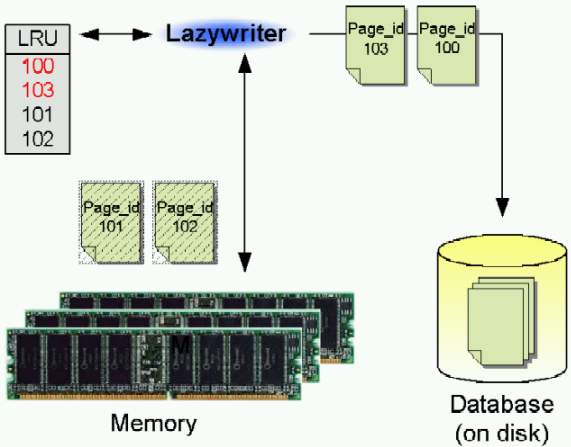
Для того чтобы записать страницы обратно на диск и освободить память, сервер SQL использует специальный поток, называемый lazywriter («ленивое перо»). Когда lazywriter записывает страницы на диск, он использует список LRU (least recently used – наиболее давно используемых) страниц для того, чтобы определить, какие страницы должны быть записаны на диск. Страницы, которые давно не использовались, находятся в начале списка LRU, в то время как недавно измененные страницы находятся в конце списка. Поэтому, часто используемые страницы могут не переписываться на диск в течение довольно длительного времени (или никогда, теоретически).
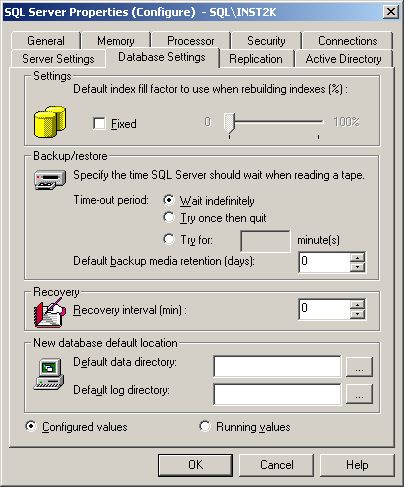
Так как страницы, которые недавно подверглись изменению, хранятся только в памяти, они чувствительны к аварийным отказам системы и выключению электропитания. Для разрешения этой проблемы сервер SQL может использовать информацию, хранящуюся в журналах, для восстановления изменений базы данных, в случае, если какое-либо из этих событий произойдет. Например, если питание выключится (и ваш UPS выйдет из строя!), мы может потерять последние изменения, хранящиеся в памяти. Для того чтобы восстановить данные страницы, сервер SQL запускает режим восстановления. Используя журнал транзакций, сервер SQL может перенести все изменения в копию базы данных, хранящуюся на жестком диске. Если ваши данные интенсивно обновляются, то это может породить и другую проблему. Как долго в данном случае будет происходить процесс восстановления? Процесс lazywriter может не переписать часто используемые страницы на жесткий диск. Кроме того, число изменений, которое придется вносить из журнала транзакций, может быть очень большим. Поэтому, количество времени, которое потребуется для восстановления базы данных после отказа, может оказаться огромным. Для решения этой проблемы, сервер SQL использует контрольные точки для сокращения времени, необходимого для восстановления базы данных в случае системного сбоя. В контрольных точках все «грязные» страницы, в которые были внесены изменения с момента последней контрольной точки, переписываются на жесткий диск. Кроме того, контрольная точка также записывает невыполненные транзакции в журнал транзакций. В случае если случится отказ системы, процесс восстановления может начать восстановление с последней контрольной точки и ему нужно будет только восстановить те транзакции, которые были произведены после последней контрольной точки или ожидали своего выполнения. Итак, когда генерируется контрольная точка? Интервал генерации контрольной точки основан на т.н. интервале восстановления, который является глобальной настройкой для экземпляра сервера SQL и определяет максимальное число минут для базы данных, которое потребуется серверу SQL для осуществления процесса восстановления. Для изменения интервала восстановления, вы можете щелкнуть правой кнопкой мыши на изображении вашего сервера SQL в дереве Диспетчера Предприятия и выбрать опцию Properties. Как только появится окно Properties, выберите вкладку Database Settings.
Значение по умолчанию для интервала восстановления равно 0. Это означает, что сервер SQL автоматически устанавливает значение интервала восстановления. Если вы оставите это значение интервала восстановления, это будет означать, что интервал генерации контрольной точки будет составлять менее одной минуты. Если сервер имеет достаточно большую память и ваша база данных подвергается большому количеству добавлений и изменений, вы можете заметить, что значение по умолчанию означает чрезмерное количество генерируемых контрольных точек. Для улучшения производительности вам потребуется установить значение интервала восстановления равным 15 или даже 30 минутам, в зависимости от максимально допустимого времени простоя. Кроме достижения значения интервала генерации контрольной точки, процесс генерации контрольной точки также происходит, когда сервер SQL или компьютер выключается должным образом. Для получения большей информации относительно интервала восстановления смотрите статью “recovery interval Option” в справочной системе Book Online сервера SQL 2000. Теперь, имея ясное понимание того, что из себя представляет транзакция, как журнал транзакции используется для процесса восстановления и как «грязные» страницы записываются на жесткий диск, давайте глубже рассмотрим, как информация о транзакциях хранится в журналах транзакций. В отличие от файлов данных, журналы транзакций не организованы в страницы по 8 КВ и они также не используют группы файлов. Когда информация о транзакциях должна быть записана в журнал, она записывается на жесткий диск в файл любого необходимого размера. Например, если записанная информация мала, ей не требуется использование 8 КВ страницы. Кроме того, если должно быть записано большое количество информации, это может быть сделано большими блоками, например, 16 или 32 КВ. Поскольку ведение журнала является периодической операцией, размещение файла журнала на отдельном собственном жестком диске или массиве дисков RAID может улучшить производительность. Для начала записи головкам диска требуется только время на перемещение в требуемое положение. В дальнейшем головки находятся в месте (или около него), где будет продолжаться запись журнала. На этом мы заканчиваем изучение материала текущей недели. Итак, куда мы двинемся дальше? Теперь, когда у вас есть хорошее понимание того, для чего используются журналы транзакций, мы можем рассмотреть различные стратегии резервного копирования. И как всегда…если у вас возникнут какие-либо технические вопросы, пожалуйста, присылайте их на доску объявлений сайта 2000Trainers.com SQL message board. Нетехнические вопросы, комментарии и обратная связь – по адресу моей электронной почты. Я надеюсь, что вы найдете эти статьи полезными и был бы рад узнать ваше мнение о них.
Mike Aubert, MCSE, MCDBA, MCSD. |